Sample语言词法分析
简介
由于编译原理课程需要完成两个实验,一个是词法分析,一个是语法、语义分析及中间代码生成(生成四元式),做完后在这留个记录,说不定有人会用到。
PS:可能程序的考虑并不完美,仅供参考和交流
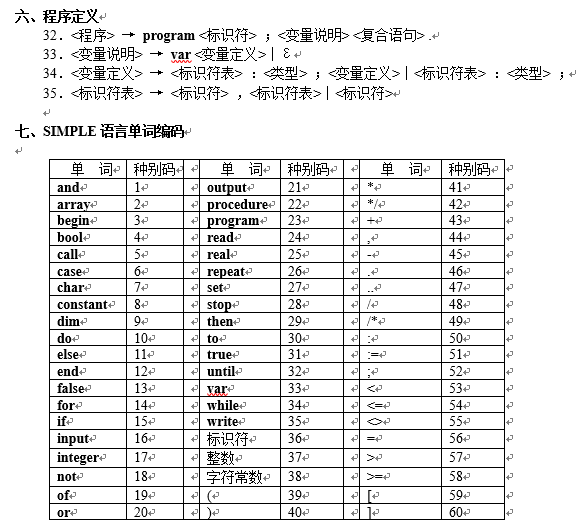
Sample语言定义
如下图为sample语言的定义


词法分析要求
实验一:设计SAMPLE语言的词法分析器
检查要求:
a) 启动程序后,先输出作者姓名、班级、学号(可用汉语、英语或拼音);
b) 请求输入测试程序名,键入程序名后自动开始词法分析并输出结果;
c) 输出结果为单词的二元式序列(样式见样板输出1和2);
d) 要求能发现下列词法错误和指出错误性质和位置:
非法字符,即不是SAMPLE字符集的符号;
字符常数缺右边的单引号(字符常数要求左、右边用单引号界定,不能跨行);
注释部分缺右边的界符*/(注释要求左右边分别用/*和*/界定,不能跨行)。
思路
按照确定的有穷自动机(DFA)的方式实现。
- 根据Sample语言的定义设计需要的状态
- 程序一个字符字符的读入,每读入一个字符后进行判断,然后转移到不同的状态
- 每个状态下输入哪个字符后状态可以转移到接受态并保存,然后返回初始状态。
- 每个状态下输入哪个字符需要报错,如注释的跨行等等。
- 双界符的判断:如注释和除法的判断。所以要用最长匹配模式,某些单、双界符的判断有时候要退回一个字符。

以注释Token的识别进行举例:
- 当输入/时,状态转换为INSLASH
- 若在INSLASH的状态,遇到*进入INCOMMENT状态,否则就转到DONE状态,INCOMMENT状态下遇到其他任何字符都不转换状态,遇到*则转移到RIGHTCOMMENT状态
- 如果RIGHTCOMMENT遇到/则注释结束,转到DONE状态。而在 RIGHTCOMMENT的情况下遇到回车以外的其他符号则转回INCOMMENT状态,若在RIGHTCOMMENT状态遇到回车,说明注释没有正常结束,进行报错。
接受态代码的处理
在DONE状态下,要单独对用户声明的标识符或者使用的保留字进行处理,首先要检查是否属于保留字,如果不是,再做其他的处理。
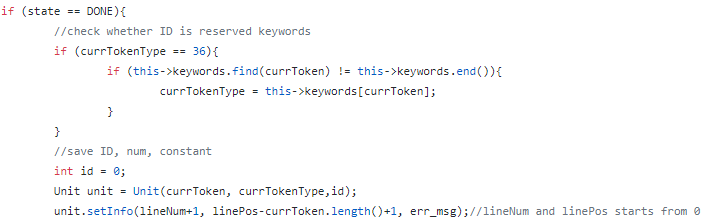
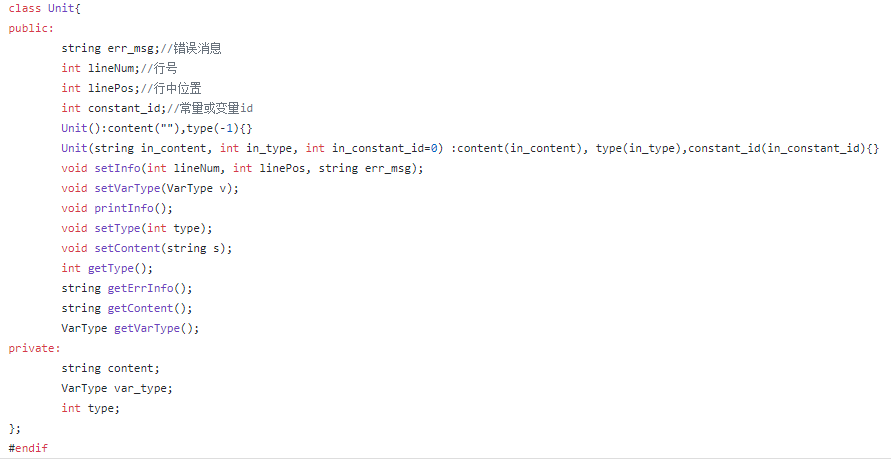
在处理完一个完成态时,要将当前的Token保存,我用的是自定义的类Unit来保存,详细的过程和属性直接看代码比较直观。
主要保存的信息是行数,列号,对应的类型,内容和报错信息等等。
代码
代码已经打包至GitHub仓库,请移步。
PS:代码是包含了两个实验的全部代码
GitHub地址
其中项目主函数在Parser.cpp中
词法分析调用函数为grammarParser.cpp中的checkWords()
小结
总的来说词法分析属于编译原理中比较简单的一块,看看实现的代码基本就能理解了。重点还是把NFA写出,转为DFA(或者直接写出DFA)。总的来说就是书上讲的词法那一块弄懂了基本词法分析就没有问题了。